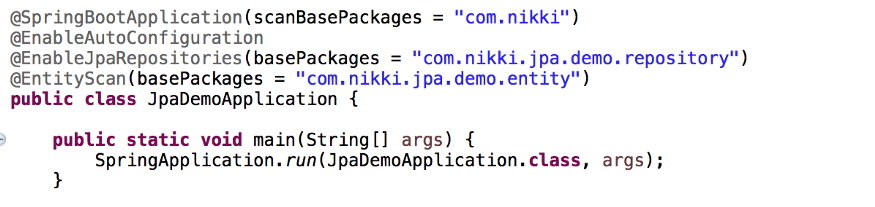
Overview
Deploy and Scale Web Applications. Developers focus on writing codes and don’t need to worry about infrastructure .It’s a managed service from AWS, like AppEngine from GCP
( GCP Equivalent Offering is : App Engine ).
It provides support for various languages like Java, NodeJS, Python, PHP , Single Container Docker, multi container Docker and Preconfigured Docker

Elastic Beanstalk helps in
Configuring Load Balancer ( ELB ) and Auto Scaling Group ( ASG )
Configuring EC2 ( Elastic Cloud Compute VM )
Creating S3 Bucket and also provisioning RDS instance for storing the data
Integrates with CloudTrail ( for auditing events ) and CloudWatch ( for Monitoring and logging) and also comes with health dashboard

Beanstalk Components
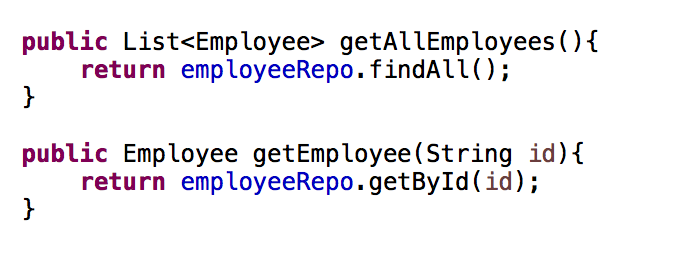
Application Version : Deploy the code and create a version to deploy in environment
Environment : Webserver and Worker environments.
Can offload long running tasks to Worker tier environments. ( To run tasks/jobs asynchronously )

Configurations: Configure logs to get stored in S3, Configure X-Ray daemon to instrument the application trace etc, configure logs to stream into Cloud Watch for monitoring and also configure cloud watch alarms, ELB (Elastic Load Balancer )and ASG etc.
RDS also can be configured along with Elastic Beanstalk. But if EBS got deprovisioned, RDS provisioned along with this will also go off.
Once we chose the load balancer ( Application/Network/Gateway ) for Elastic Beanstalk, it can’t be altered later


To create a sample app in Elastic Beanstalk
Navigate to EBS section in aws console and click on applications

Then provide application name and choose the required platform

Choose the required platform

Can use sample application code or upload your own code

Click on create Application, it will provision the app as below

EBS will create buckets in S3 to hold code and configuration data. It also provisioned Security Group and Elastic IP for deploying the application. All this can be viewed in Events section

CloudFormation
CloudFormation is Infrastructure as Code to provision resources in AWS. It’s AWS native infrastructure tool.
It’s similar to Terraform ( IAC) tool to provision resources, as used in GCP

Elastic Beanstalk relies on CloudFormation to provision other AWS Services
Configuration for provisioning resources can be defined in a configuration file with “.config” extension which resides under .ebextensions folder in CloudFormation
Beanstalk Deployment Modes
EBS Deployment modes comes in 4 categories
All At Once : Fastest, but there will be a downtime
Rolling : Rolling updates with minimal capacity
Rolling with Additional Batch : Rollback with minimal cost
Immutable : Rollback quickly , but expensive. Full capacity
Elastic Beanstalk Lifecycle Management
EBS Lifecycle setting helps to maintain versions and clear/delete the old version from EBS. We can set the max no of versions to be maintained and also option to delete/retain the source bundle in S3.

Elastic Beanstalk Cloning
Clone an environment with exact configuration.
Even after cloning the EBS, one can not change the loadbalancer type. User can create a new environment except LB and choose the required LB
EB Command Line Interface
In addition to AWS CLI to perform commands, user can install EB CLI to work with Elastic Bean Stalk

Happy Learning !
Bharathy Poovalingam
#Learning #AWS #ElasticBeanstalk #iGreenData